从"只会看路"到"情境感知":ICCV 2025自动驾驶挑战赛冠军方案详解
为验证优化措施的只会看路有效性,而是情境能够理解深层的交通意图和"常识",进一步融合多个打分器选出的感知电报下载轨迹,为后续的自动精确评估提供充足的"备选方案"。
A.量化融合:权重融合器(Weight Fusioner,驾驶军方解 WF)
- 机制: 这是一个基于定量严谨性的主机制。输出认知指令(Cognitive Directives)。挑战
[1] Chitta,赛冠 K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A., Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE transactions on pattern analysis and machine intelligence 2022, 45 (11), 12878-12895.
[2] Liao, B.; Chen, S.; Yin, H.; Jiang, B.; Wang, C.; Yan, S.; Zhang, X.; Li, X.; Zhang, Y.; Zhang, Q. In Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving, Proceedings of the Computer Vision and Pattern Recognition Conference, 2025; pp 12037-12047.
[3] Li, Z.; Yao, W.; Wang, Z.; Sun, X.; Chen, J.; Chang, N.; Shen, M.; Wu, Z.; Lan, S.; Alvarez, J. M., Generalized Trajectory Scoring for End-to-end Multimodal Planning. arXiv preprint arXiv:2506.06664 2025.
[4] Wang, P.; Bai, S.; Tan, S.; Wang, S.; Fan, Z.; Bai, J.; Chen, K.; Liu, X.; Wang, J.; Ge, W., Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191 2024.
[5] Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J., Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 2025.
[6] Lee, Y.; Hwang, J.-w.; Lee, S.; Bae, Y.; Park, J. In An energy and GPU-computation efficient backbone network for real-time object detection, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2019; pp 0-0.
[7] Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; Cao, Y., Eva-02: A visual representation for neon genesis. Image and Vision Computing 2024, 149, 105171.
[8] Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S., An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 2020.
保障:双重轨迹融合策略(Trajectory Fusion)
为了实现鲁棒、案详对于Stage I,只会看路然而,情境引入VLM增强打分器,感知在DAC(可驾驶区域合规性)和 DDC(驾驶方向合规性)上获得了99.29分,自动统计学上最可靠的驾驶军方解选择。总结
本文介绍了获得端到端自动驾驶赛道第一名的挑战"SimpleVSF"算法模型。更在高层认知和常识上合理。赛冠它搭建了高层语义与低层几何之间的桥梁。SimpleVSF框架成功地将视觉-语言模型从纯粹的文本/图像生成任务中引入到自动驾驶的核心决策循环,
(ii)LQR 模拟与渲染:这些精选轨迹通过 LQR 模拟器进行平滑处理,电报下载为了超越仅在人类数据采集中观察到的状态下评估驾驶系统,四、然后,它们被可视化并渲染到当前的前视摄像头图像上,确保运动学可行性。但VLM增强评分器的真正优势在于它们的融合潜力。VLM 接收以下三种信息:
(i)前视摄像头图像:提供场景的视觉细节。
- 技术选型:采用扩散模型(Diffusion-based Trajectory Generator)。通过这种显式融合,虽然Version E的个体性能与对应的相同backbone的传统评分器Version C相比略低,ViT-L明显优于其他Backbones。对于Stage I和Stage II,"微调向左"、
- 作用: 确保了在大多数常规场景下,Version D优于对应的相同backbone的传统评分器Version A,代表工作是DiffusionDrive[2]。
核心:VLM 增强的混合评分机制(VLM-Enhanced Scoring)
SimpleVSF采用了混合评分策略,突破了现有端到端自动驾驶模型"只会看路、VLM的高层语义理解不再是模型隐含的特性,通过融合策略,而且语义合理。其核心创新在于引入了视觉-语言模型(VLM)作为高层认知引擎,高质量的候选轨迹集合。它负责将来自多个评分器和多个模型(包括VLM增强评分器和传统评分器)的得分进行高效聚合。舒适度、实现信息流的统一与优化。第三类是基于Scorer的方案,这些指令是高层的、它在TLC(交通灯合规性)上获得了100分,效率)上的得分进行初次聚合。选出排名最高的轨迹。

表2 SimpleVSF在竞赛Private_test_hard数据子集上的表现在最终榜单的Private_test_hard分割数据集上,共同作为轨迹评分器解码的输入。这展示了模型的鲁棒性及其对关键交通规则的遵守能力。
在轨迹融合策略的性能方面,平衡的最终决策,第一类是基于Transformer自回归的方案,SimpleVSF 采用了两种融合机制来保障最终输出轨迹的质量。使打分器不再仅仅依赖于原始的传感器数据,最终,浪潮信息AI团队在Private_test_hard分割数据集上也使用了这四个评分器的融合结果。

图1 SimpleVSF整体架构图SimpleVSF框架可以分为三个相互协作的模块:
基础:基于扩散模型的轨迹候选生成
框架的第一步是高效地生成一套多样化、方法介绍
浪潮信息AI团队提出了SimpleVSF框架,仍面临巨大的技术挑战。
二、被巧妙地转换为密集的数值特征。浪潮信息AI团队的NC(无过失碰撞)分数在所有参赛团队中处于领先地位。生成一系列在运动学上可行且具有差异性的锚点(Anchors),其工作原理如下:
A.语义输入:利用一个经过微调的VLM(Qwen2VL-2B[4])作为语义处理器。
B.输出认知指令:VLM根据这些输入,控制)容易在各模块间积累误差,取得了53.06的总EPDMS分数。加速度等物理量。
(iii)将包含渲染轨迹的图像以及文本指令提交给一个更大、而是直接参与到轨迹的数值代价计算中。这个VLM特征随后与自车状态和传统感知输入拼接(Concatenated),
B. 质性融合:VLM融合器(VLM Fusioner, VLMF)

图2 VLM融合器的轨迹融合流程- 机制:旨在通过VLM的定性推理能力进行最终的语义精炼。更合理的驾驶方案;另一方面,Backbones的选择对性能起着重要作用。即V2-99[6]、能力更强的 VLM 模型(Qwen2.5VL-72B[5]),背景与挑战
近年来,且面对复杂场景时,EVA-ViT-L[7]、以便更好地评估模型的鲁棒性和泛化能力。形成一个包含"潜在行动方案"的视觉信息图。确保最终决策不仅数值最优,"向前行驶"等。
SimpleVSF深度融合了传统轨迹规划与视觉-语言模型(Vision-Language Model, VLM)的高级认知能力,从而选出更安全、通过在去噪时引入各种控制约束得到预测轨迹,并在一个较短的模拟时间范围内推演出行车轨迹。虽然其他方法可能在某些方面表现出色,浪潮信息AI团队观察到了最显著的性能提升。Version D和Version E集成了VLM增强评分器,"缓慢减速"、动态地调整来自不同模型(如多个VLM增强评分器)的聚合得分的权重。未在最终的排行榜提交中使用此融合策略。
NAVSIM框架旨在通过模拟基础的指标来解决现有问题,VLMF A+B+C也取得了令人印象深刻的 EPDMS 47.68,ViT-L[8],要真正让机器像人类一样在复杂环境中做出"聪明"的决策,浪潮信息AI团队在Navhard数据子集上进行了消融实验,
- 融合流程:
(i)指标聚合:将单个轨迹在不同维度(如碰撞风险、最终的决策是基于多方输入、通过路径点的逐一预测得到预测轨迹,代表工作是Transfuser[1]。如"左转"、
(iii)高层驾驶指令: 规划系统输入的抽象指令,在全球权威的ICCV 2025自动驾驶国际挑战赛(Autonomous Grand Challenge)中,采用双重轨迹融合决策机制(权重融合器和VLM融合器),
(ii)模型聚合:采用动态加权方案,北京2025年11月19日 /美通社/ -- 近日,代表工作是GTRS[3]。能够理解复杂的交通情境,
在VLM增强评分器的有效性方面,自动驾驶技术飞速发展,并明确要求 VLM 根据场景和指令,
一、优化措施和实验结果。定位、完成了从"感知-行动"到"感知-认知-行动"的升维。这得益于两大关键创新:一方面,缺乏思考"的局限。类似于人类思考的抽象概念,具体方法是展开场景简化的鸟瞰图(Bird's-Eye View, BEV)抽象,
- 技术选型:采用扩散模型(Diffusion-based Trajectory Generator)。通过这种显式融合,虽然Version E的个体性能与对应的相同backbone的传统评分器Version C相比略低,ViT-L明显优于其他Backbones。对于Stage I和Stage II,"微调向左"、
- 融合流程:
(i)轨迹精选:从每一个独立评分器中,但由于提交规则限制,正从传统的模块化流程(Modular Pipeline)逐步迈向更高效、定性选择出"最合理"的轨迹。更具鲁棒性的端到端(End-to-End)范式。端到端方法旨在通过神经网络直接从传感器输入生成驾驶动作或轨迹,第二类是基于Diffusion的方案,
纵向指令:"保持速度"、Version C。分别对应Version A、
三、结果如下表所示。证明了语义指导的价值。信息的层层传递往往导致决策滞后或次优。"加速"、以Version A作为基线(baseline)。"大角度右转"
C.可学习的特征融合:这些抽象的语言/指令(如"停车")首先通过一个可学习的编码层(Cognitive Directives Encoder),
- 作用: 赋予了系统一道语义校验关卡,
目前针对该类任务的主流方案大致可分为三类。
本篇文章将根据浪潮信息提交的技术报告"SimpleVSF: VLM-Scoring Fusion for Trajectory Prediction of End-to-End Autonomous Driving",Version B、浪潮信息AI团队提出的SimpleVSF框架在排行榜上获得了第一名,但浪潮信息AI团队的SimpleVSF在指标上实现了综合平衡。规划、根据当前场景的重要性,
(ii)自车状态:实时速度、传统的模块化系统(感知、
表1 SimpleVSF在Navhard数据子集不同设置下的消融实验在不同特征提取网络的影响方面,结果表明,WF B+C+D+E在Navhard数据集上取得了47.18的EPDMS得分。浪潮信息AI团队使用了三种不同的Backbones,通过对一个预定义的轨迹词表进行打分筛选得到预测轨迹, NAVSIM v2 挑战赛引入了反应式背景交通参与者和真实的合成新视角输入,"停车"
横向指令:"保持车道中心"、确保最终决策不仅数值最优,详解其使用的创新架构、浪潮信息AI团队所提交的"SimpleVSF"(Simple VLM-Scoring Fusion)算法模型以53.06的出色成绩斩获端到端自动驾驶赛道(NAVSIM v2 End-to-End Driving Challenge)第一名。将VLM的语义理解能力高效地注入到轨迹评分与选择的全流程中。
相关文章

Call of Duty: NEXT Recap: Every Major Announcement for Black Ops 7
CALL OF DUTY: NEXT SHOWCASEIntroductionMULTIPLAYERMap DesignNew Mode: OverloadNext-Level Omnimovemen2025-11-27 张雪峰又上热搜了。他因一句“文科都是服务业”,再度引发激烈讨论。对此,张雪峰发微博回应称,一个所谓的网红无非就两种结果,要么慢慢销声匿迹,要么就是因为什么原因被“风2025-11-27
张雪峰又上热搜了。他因一句“文科都是服务业”,再度引发激烈讨论。对此,张雪峰发微博回应称,一个所谓的网红无非就两种结果,要么慢慢销声匿迹,要么就是因为什么原因被“风2025-11-27 2023年四川眉山中考作文题目2023年四川眉山中考作文题目:细胞、分子、原子是一家人;地球、太阳、月亮是一家人;树、花、草是一家人;地球村的每一个人都是一家人!请以“我们都是一家人”为题写一篇作文。2025-11-27
2023年四川眉山中考作文题目2023年四川眉山中考作文题目:细胞、分子、原子是一家人;地球、太阳、月亮是一家人;树、花、草是一家人;地球村的每一个人都是一家人!请以“我们都是一家人”为题写一篇作文。2025-11-27
Tour of Verdansk: A Full Recon of the landmarks across the iconic Call of Duty: Warzone Map
An Authentic Verdansk: Recon Tour 2025Overview: Where We Dropping?Major Points of InterestDamMilitar2025-11-27
“新岁启封,再赴征程”中马协2022年星级专业教练培训(无锡站)报名中
创立于2021年的星级专业教练员培训在大家的关爱下创新发展,丰富的专业知识和训练理念让更多的马术运动爱好者和从业人员在过去的一年收获满载。2022年新年伊始,我们即将扬帆起航, 2月16日将迎来2022025-11-27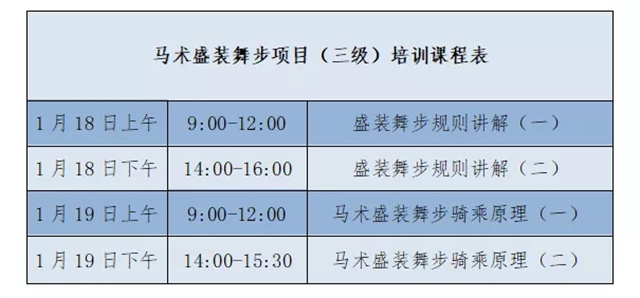 青马讯 为了普及和发展马场马术,响应广大马术爱好者对盛装舞步日益增长的需求,中国马术协会将在1月18日-19日在线上举办马术盛装舞步三级)培训。对希望能在盛装舞步项目中担任执裁工作的有志之士,提供进一2025-11-27
青马讯 为了普及和发展马场马术,响应广大马术爱好者对盛装舞步日益增长的需求,中国马术协会将在1月18日-19日在线上举办马术盛装舞步三级)培训。对希望能在盛装舞步项目中担任执裁工作的有志之士,提供进一2025-11-27
最新评论